
本文截图均没有打码,请勿在公共场合打开,以免造成不必要的尴尬。。。
先简要说一下我的环境和需求,我是在mgstage上买了一些网上没出种或者出种很慢的片,然后通过解密的方式把片下载到本地电脑,为了能够在其他设备上方便观看,我会把本地电脑的片通过nextcloud同步到服务器上面。
现在遇到的一个问题是,随着日积月累,同步到nextcloud上面的片子越来越多,有时候想看某部片就变得非常难查找,然后就想着搞个类似jellyfin、emby的媒体系统来整理一下,经过再三考虑,最终还是选择用stash了。
准备工作
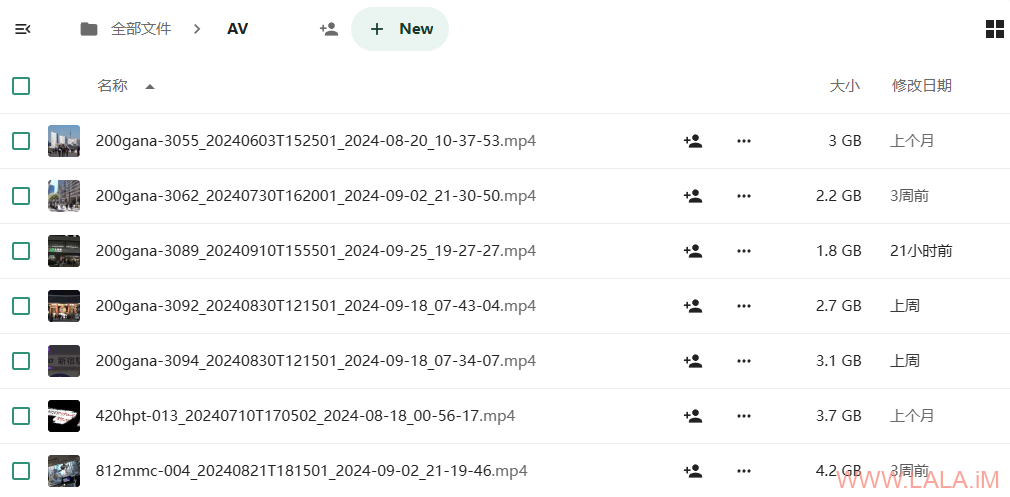
我在服务器上面安装的是nextcloud aio,然后我在nextcloud里面新建了一个文件夹名为AV,所有的片都同步到了这个文件夹下面:
现在首先要知道同步到服务器的片具体存在哪里,通过执行命令:
docker volume ls
得知nextcloud aio用了这些卷:
DRIVER VOLUME NAME local nextcloud_aio_apache local nextcloud_aio_database local nextcloud_aio_database_dump local nextcloud_aio_elasticsearch local nextcloud_aio_mastercontainer local nextcloud_aio_nextcloud local nextcloud_aio_nextcloud_data local nextcloud_aio_redis
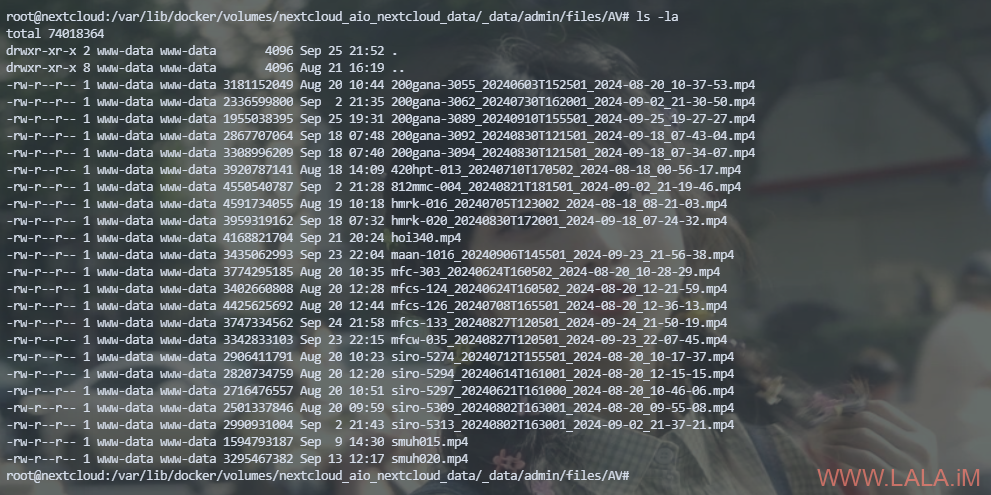
看名字的话用户数据应该都存在nextcloud_aio_nextcloud_data这个卷里面,只是初步猜测。
去验证一下到底是不是,docker默认的卷数据都存在/var/lib/docker/volumes下面。
确认是nextcloud_aio_nextcloud_data这个卷没错就行:
安装stash
现在来安装stash,新建需要用到的目录和compose文件:
mkdir -p /opt/stash && cd /opt/stash && nano docker-compose.yml
先暂时写入如下配置(待会还需要修改):
services:
stash:
image: stashapp/stash:latest
container_name: stash
restart: unless-stopped
ports:
- "9999:9999"
logging:
driver: "json-file"
options:
max-file: "10"
max-size: "2m"
environment:
- STASH_STASH=/data/
- STASH_GENERATED=/generated/
- STASH_METADATA=/metadata/
- STASH_CACHE=/cache/
- STASH_PORT=9999
volumes:
- /etc/localtime:/etc/localtime:ro
- ./config:/root/.stash
- nextcloud_aio_nextcloud_data:/data
- ./metadata:/metadata
- ./cache:/cache
- ./blobs:/blobs
- ./generated:/generated
volumes:
nextcloud_aio_nextcloud_data:
external: true
启动:
docker compose up -d
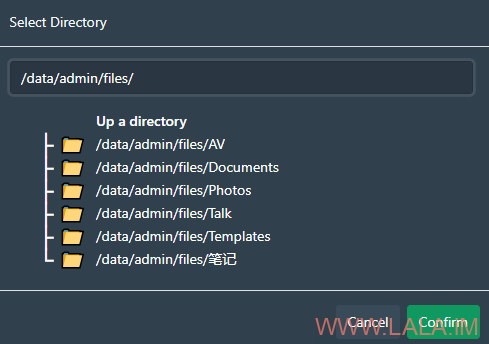
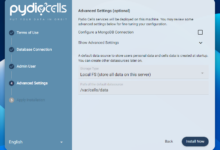
访问服务器IP:9999开始安装向导,这里需要配置媒体目录,在之前我们把nextcloud_aio_nextcloud_data挂载进来了,所以stash也能访问到这个卷里面的数据,直接选择之前的AV文件夹即可:
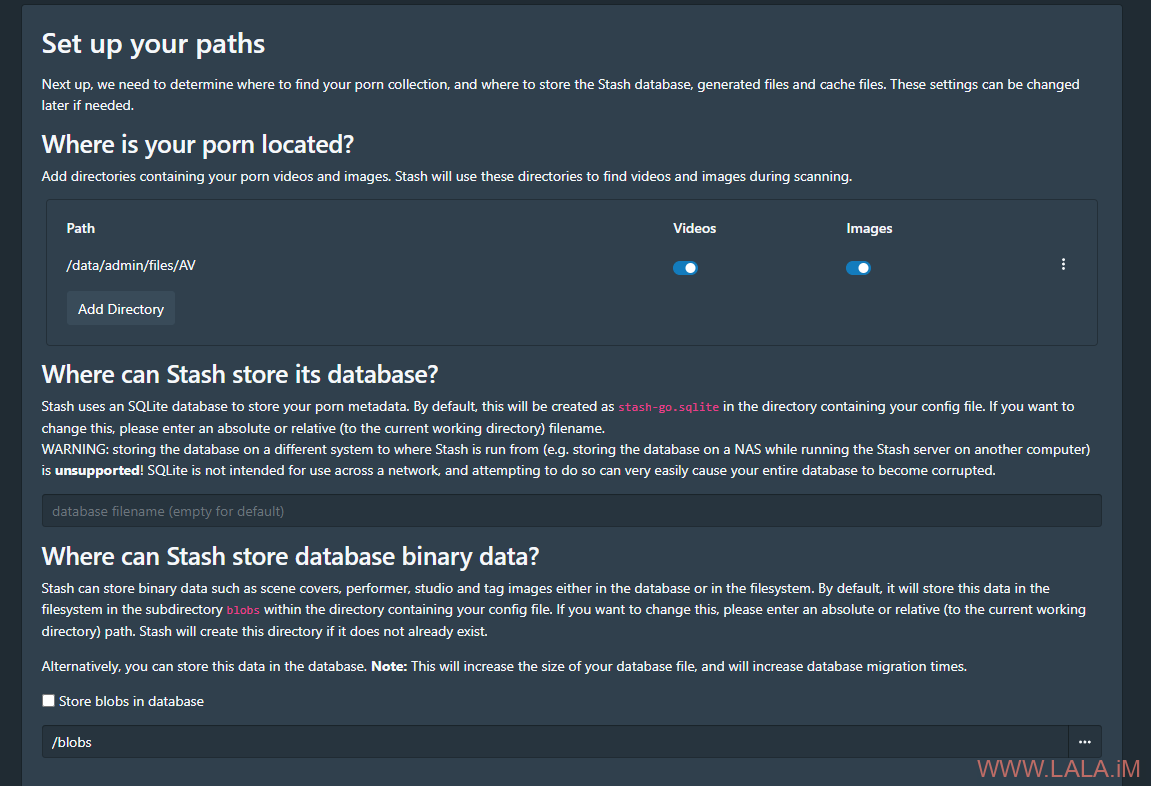
除此之外还需要配置一下blobs的路径,最终配置如下:
继续下一步就安装完成了,之后你会发现报错了,报了个什么403错误,其实没关系这是因为stash的安全机制生效了,默认情况下stash不允许从公网访问,现在要做的就是配置stash暂时允许公网访问。
配置stash暂时允许公网访问
编辑stash的配置文件:
nano config/config.yml
修改如下配置的值为true:
dangerous_allow_public_without_auth: "true"
修改如下配置的值为空:
security_tripwire_accessed_from_public_internet: ""
重启stash生效:
docker compose down docker compose up -d
访问服务器IP:9999,应该能看到stash的界面了,进来之后首先找到安全性->认证设置->账户凭证,设置你的账号密码:
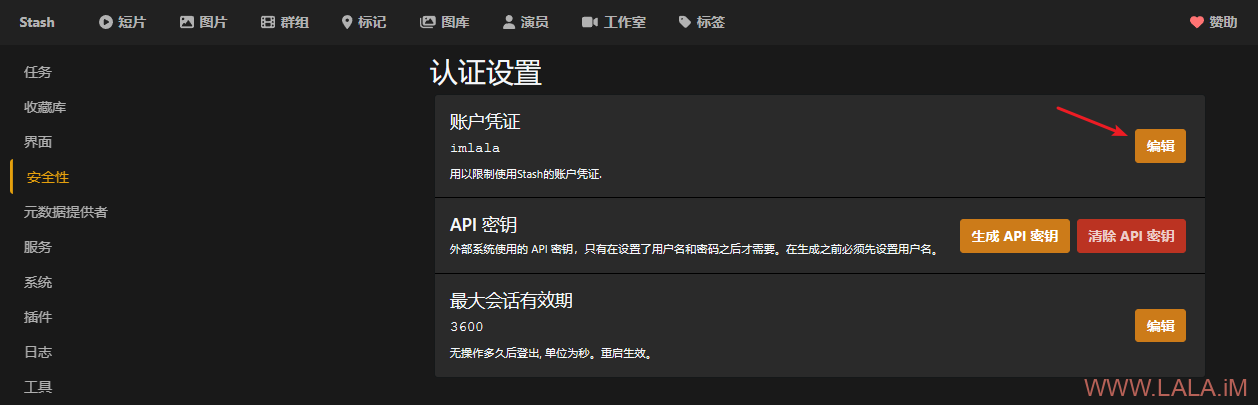
这样设置之后访问stash就需要身份验证了,会跳转到登录页面,提示让你输入账号密码进行登录。
配置反向代理
将stash暴露在公网上,最好还是配置一个反向代理。安装需要用到的包:
apt -y update apt -y install nginx python3-certbot-nginx
编辑stash的配置文件:
nano config/config.yml
增加如下配置:
external_host: https://stash.example.com
编辑compose文件:
nano docker-compose.yml
修改之前的端口映射配置,将stash的9999端口仅监听在本地:
services:
stash:
image: stashapp/stash:latest
container_name: stash
restart: unless-stopped
ports:
- "9999:9999"
- "127.0.0.1:9999:9999"
logging:
driver: "json-file"
options:
max-file: "10"
max-size: "2m"
environment:
- STASH_STASH=/data/
- STASH_GENERATED=/generated/
- STASH_METADATA=/metadata/
- STASH_CACHE=/cache/
- STASH_PORT=9999
volumes:
- /etc/localtime:/etc/localtime:ro
- ./config:/root/.stash
- nextcloud_aio_nextcloud_data:/data
- ./metadata:/metadata
- ./cache:/cache
- ./blobs:/blobs
- ./generated:/generated
volumes:
nextcloud_aio_nextcloud_data:
external: true
重启stash生效:
docker compose down docker compose up -d
新建nginx站点配置文件:
nano /etc/nginx/sites-available/stash
写入如下配置:
server {
listen 80;
listen [::]:80;
server_name stash.example.com;
client_max_body_size 0;
location / {
proxy_pass http://127.0.0.1:9999;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "Upgrade";
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Port $server_port;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
启用站点:
ln -s /etc/nginx/sites-available/stash /etc/nginx/sites-enabled/stash
签发tls证书:
certbot --nginx --email imlala@example.com --agree-tos --no-eff-email
现在就可以通过stash.example.com域名来访问stash了,登录进去后,可以在界面->语言选择中文:
配置stash扫描入库
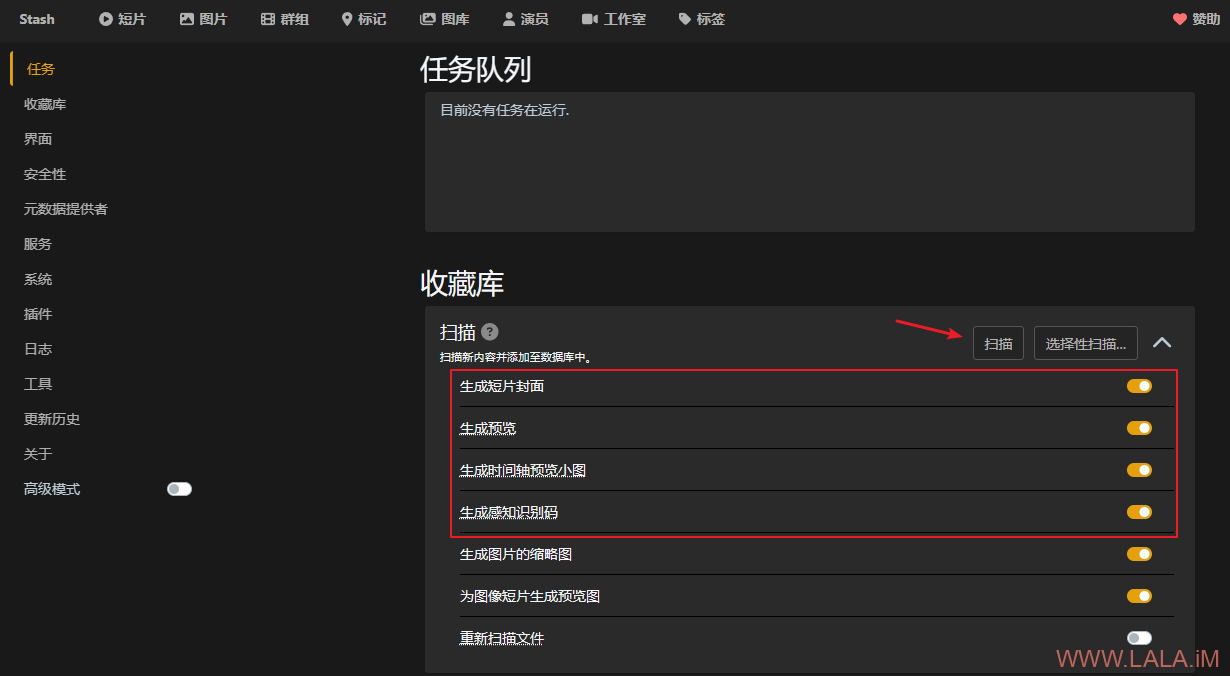
接下来就可以把影片入库到stash了,找到任务->收藏库->扫描->勾选如图所示内容,然后点击扫描,开始入库:
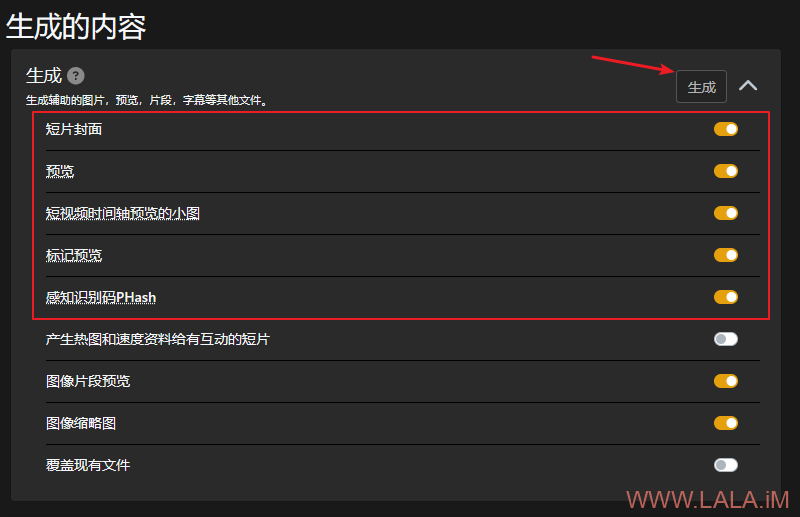
等入库完成后,找到生成的内容,勾选如图所示选项,然后点击生成:
安装刮削插件
影片入库完了之后,最重要的一步来了:刮削。
所谓刮削其实就是把片子的封面、介绍、片商等元数据信息通过某个网站爬下来。
stash有一个社区项目,里面有大量的刮削插件,并且刮削插件安装起来非常简单,直接在stash界面找到元数据提供者->可用刮削器,可以一次性勾选所有刮削器,然后点击安装即可:
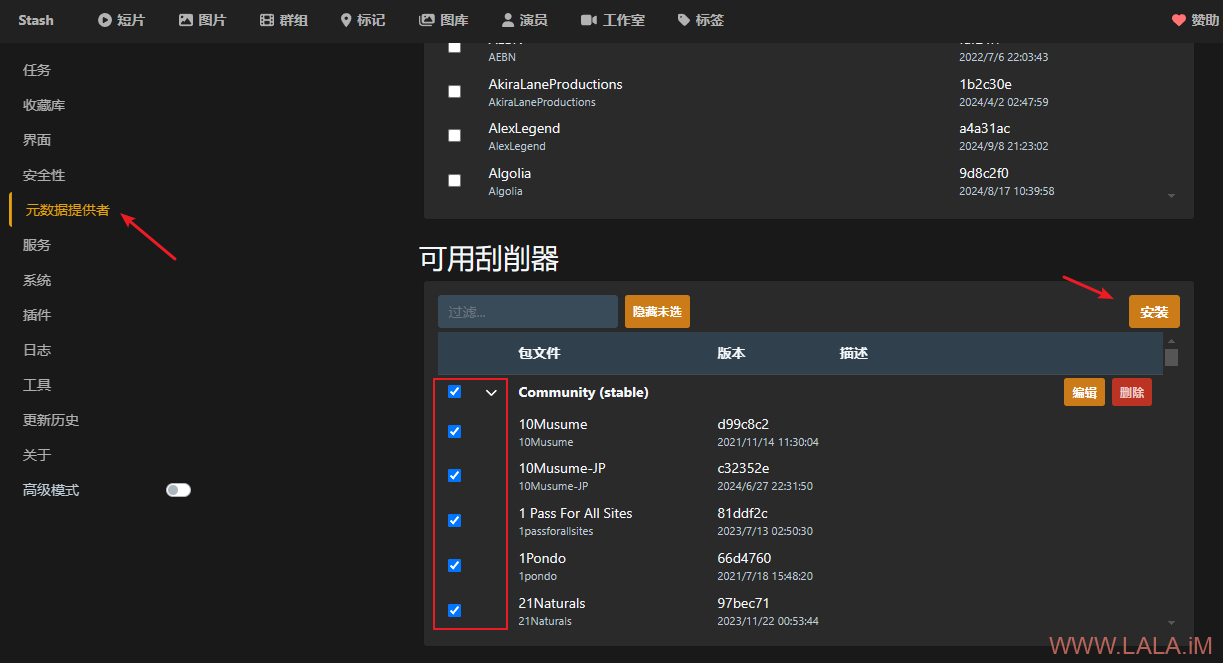
使用刮削器
现在就可以尝试刮削了,找到短片->标签工具->源,这个源就是我们刚才安装的各种刮削插件对应支持的站点。
对于jav而言,其实这里的大部分站点都不怎么好用,数据都不怎么全,我测试下来只有一个javdb是最好用的,所以要刮削jav的话就用这个javdb就行了。。但是javdb应该是有反爬机制,短时间内别太猛,我之前就是直接给干成403了。。
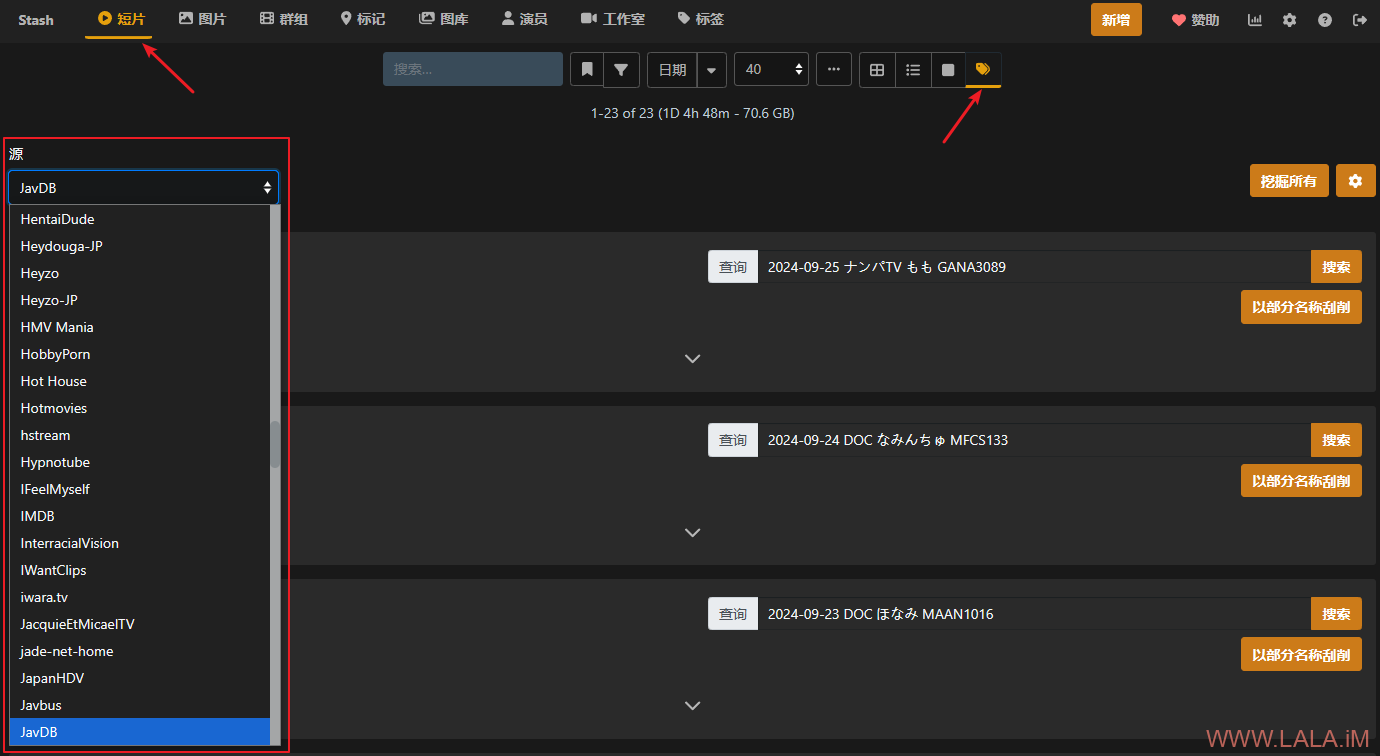
这个页面其实是批量刮削的,在选好源后,此时点击右边的“挖掘所有”按钮后会自动尝试刮削所有影片的元数据信息,但你会发现基本上毛都刮不到。。
所以这个时候就只能手动刮削了,还是在这个页面,你会发现每部影片都对应有一个查询搜索的功能,对没错就是你想的那样,很原始,在这个查询栏直接把对应影片的番号输进去,点搜索即可。。
最终效果:
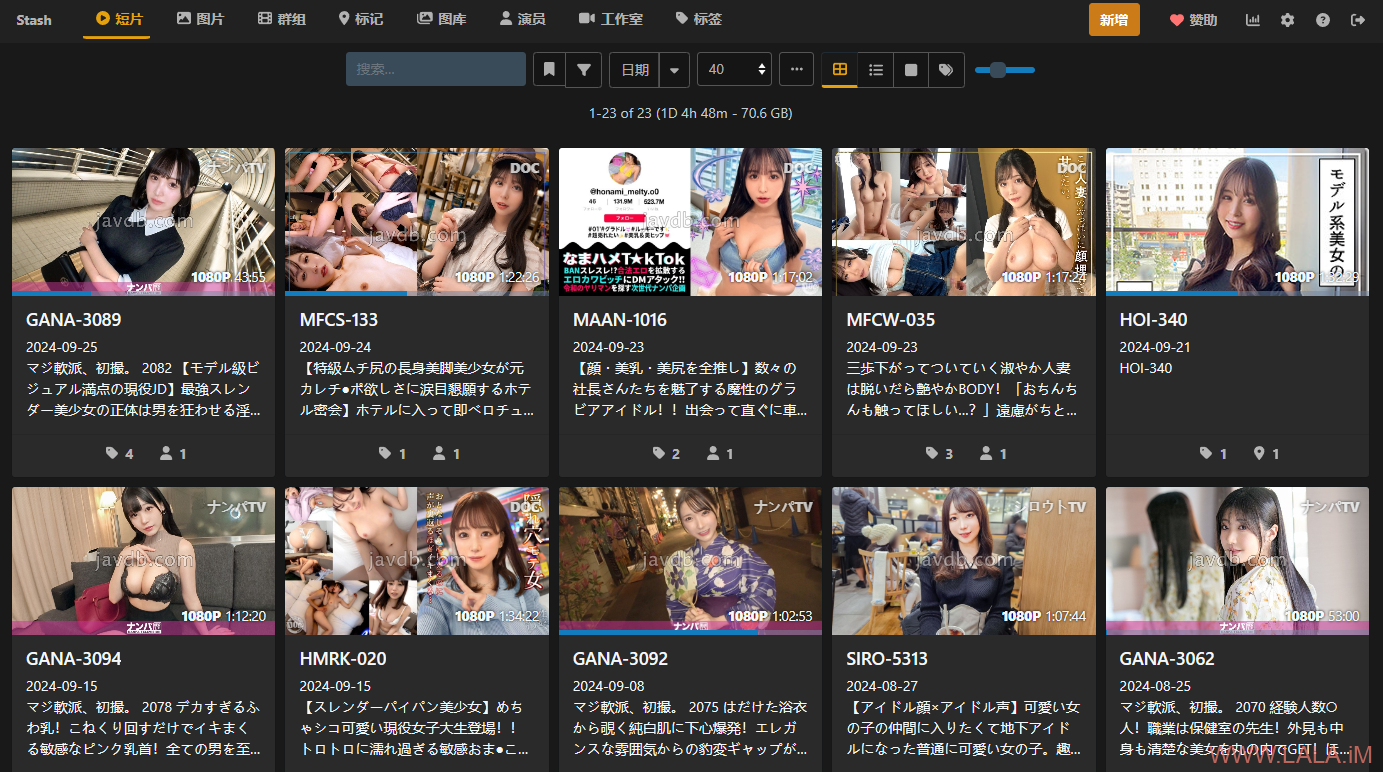
其实最后刮削下来的数据我是不太满意的,比如说女优的姓名基本都不对,但是这个也不能怪刮削插件,因为别说javdb了,就是一手站mgstage上面给的姓名大部分也是假的,要真名只能去av-wiki这类网站找。。要是哪天能支持av-wiki就好了。。


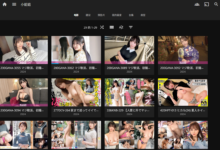

你是GGMM
lala的片库真是完善,动辄两个小时的双排多排能完整看完吗
我都是进度条拖着看,只看有性趣的部分,每部片都完整看完的是什么神仙
不是不想刮削,而是數據像你所說的出入不是一般大,是非常大,所以我現在都佛係了,把圖片和視頻改同一個名字丟到同一個文件夾,EMBY再映射這個文件夾,掃描出來圖片加名字就算了,再來內網穿透,無論何時何地什麼設備都能播放,全在Nas上一條龍服務 ,不過想方便快捷,還是搞個CMS自動導入採集站的資源,數十萬的資源想不精盡人亡都難
,不過想方便快捷,還是搞個CMS自動導入採集站的資源,數十萬的資源想不精盡人亡都難 
确实是的,感觉刮完只有封面有点用。。而且还要配代理,很多站都要日本和美国的IP才能爬到数据。我后来又发现jellyfin有个metatube的插件,不知道这个是不是稍微好点。

另外求cms自动导入采集站姿势
现在大多插件都是用不了,主要主程序的问题,插件之路我以前在Emby上走太多冤枉路,所以变得佛系了,苹果CMS-V10:https://www.maccms.cn/doc/v10/。采集站:https://senlinzy.com。
你的视频库让我同步下,哈哈
公开下视频库,爱看
博主可以告知一下这个字体的名称吗?
你是说我博客的这个字体吗?如果是的话,我自己也不记得名字了。。
字体的地址在这:https://cdn.jsdelivr.net/gh/xiya233/cdn@1.0/storage/moonbridge.woff
我选择jellyfin+metatube插件
正确的选择,我后来也搭建了一套这个发现metatube刮削JAV数据比stash强很多。
woaav.cc 福利库